Table of Contents:
- Introduction (1/11)
- Goals and Architecture (2/11)
- The inotify API (3/11)
- File Watcher, C++ (4/11)
- File Watcher, Bash (5/11)
- Execution Engine (6/11)
- Containerization (7/11)
- Kubernetes (8/11)
- Demo (9/11)
- Conclusion (10/11)
- System Setup (11/11)
- Source code
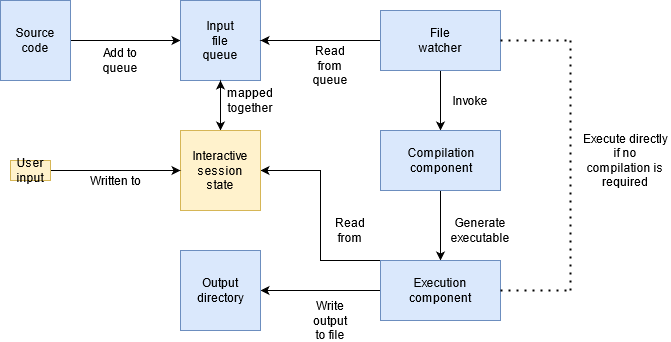
This post will cover the execution component of the multi-language compiler. If you’re still reading, then congratulations! This is the last component of the system and a not too complicated one at that. The execution component has two tasks: provide input (if necessary) and capture output. The approach taken here will be to connect a pseudoterminal to the executing process so that input/output can easily be captured by reading or writing to those streams.
The execution component splits these tasks up into individual threads:
- Main thread: connect the pseudoterminal, execute the code, and wait for the timeout value to hit or for the process to exit
- Reader thread: select on the pseudoterminal file descriptor and write the output to the output file.
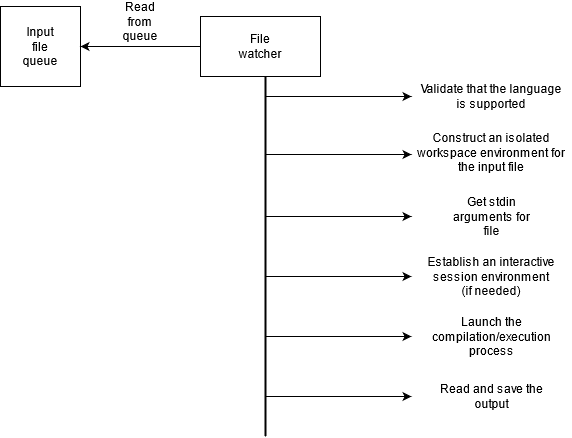
- Writer thread: monitor the stdin input file via inotify. On a change, read that change and write it to the stdin of the pseudoterminal file descriptor.
Main thread
The code to connect the pseudoterminal, launch the chilld process, and wait for its return is pretty straightforward. These are all done with provided system APIs, namely forkpty, execv, and waitpid. The snippet to accomplish this is shown below:
....
int masterFileDescriptor = -1;
pid_t childProcessId = forkpty(&masterFileDescriptor, NULL, NULL, NULL);
int childReturnCode = -1;
if (childProcessId == -1)
{
perror("forkpty");
exit(-1);
}
if (childProcessId == 0)
{
int result = execv(options.BinaryToExecute.c_str(), options.BinaryArguments.data());
exit(result);
}
else
{
std::thread(ListenForOutput, masterFileDescriptor, options.OutputFilePath)
.detach();
if (options.IsInteractive)
{
std::thread(ListenForInput, masterFileDescriptor, options.InputFilePath)
.detach();
}
childReturnCode = WaitForCloseOrTimeout(childProcessId, options.MaxWaitTimeMs);
}
return childReturnCode;
}
What is shown in the code is exactly what was described above: the execution component creates a new process with a pseudoterminal attached. This process gets passed any command line arguments to it, and then the thread that listens for output is launched. If this is an interactive session (user can provide stdin input at runtime) then the thread that listens for input is launched as well. The process then runs and returns its return code to the execution component, which subsequently returns it to the script that invoked it.
The WaitForCloseOrTimeout function is just a wrapper around waitpid that polls the child exit code up to a maximum timeout value. If the timeout has been hit then the child process is killed and 124 is returned as the timeout exit code; otherwise if the process exits within the allotted time then its exit code is returned. The WaitForCloseOrTimeout function is shown below:
pid_t WaitForCloseOrTimeout(const pid_t childProcessId, const int maxWaitTimeMs)
{
int childReturnCode = -1;
constexpr int sleepTimeMicroseconds = 100000;
int elapsedTimeMs = 0;
bool timeoutExpired = false;
bool childExited = false;
while (!timeoutExpired && !childExited)
{
int result = waitpid(childProcessId, &childReturnCode, WNOHANG);
if (result == -1)
{
perror("waitpid");
}
if (result == childProcessId)
{
childExited = true;
}
usleep(sleepTimeMicroseconds);
elapsedTimeMs += sleepTimeMicroseconds / 1000;
timeoutExpired = (elapsedTimeMs >= maxWaitTimeMs);
}
if (timeoutExpired)
{
constexpr int timeoutReturnCode = 124;
childReturnCode = timeoutReturnCode;
kill(-childProcessId, SIGTERM);
}
return childReturnCode;
}
Reader thread
The reader thread is as straightforward as can be: in a loop we read the output and write it to a file.
void ListenForOutput(const int masterFileDescriptor, const std::string outputFilePath)
{
g_outputFile.rdbuf()->pubsetbuf(0, 0);
g_outputFile.open(outputFilePath, std::ios::out);
constexpr int BUFFERSIZE = 1024;
std::array<char, BUFFERSIZE> buffer;
fd_set fileDescriptors = { 0 };
while (true)
{
FD_ZERO(&fileDescriptors);
FD_SET(masterFileDescriptor, &fileDescriptors);
if (select(masterFileDescriptor + 1, &fileDescriptors, NULL, NULL, NULL) > 0)
{
auto bytesRead = read(masterFileDescriptor, buffer.data(), buffer.size());
if (bytesRead > 0)
{
g_outputFile.write(buffer.data(), bytesRead);
}
}
}
}
Writer thread
The writer thread is a bit more complex. This thread needs to monitor the stdin file that contains the state of the interactive session. When writes are performed to this session file, the thread will need to read where the write occurred and write it to the stdin of the execution process. Since writes can happen multiple times to the session file, the last written offset must be kept track of. The full logic then is:
- Add an inotify watch on the interactive session file for IN_CLOSE_WRITE events
- On a close write event, read the file from the last offset to the end of file
- Write this read data to the stdin of the executing process
The code snippet to accomplish this is shown below:
...
if (pEvent->mask & IN_CLOSE_WRITE)
{
std::string fileName = pEvent->name;
if (fileName == stdinFileName)
{
std::ifstream file(inputFileFullPath, std::ios::in | std::ios::binary);
std::vector<char> contents;
file.seekg(lastReadOffset, std::ios::end);
contents.reserve(file.tellg());
file.seekg(lastReadOffset, std::ios::beg);
contents.assign((std::istreambuf_iterator<char>(file)),
std::istreambuf_iterator<char>());
lastReadOffset += contents.size();
size_t bytesWritten = 0;
do
{
ssize_t written = write(masterFileDescriptor, contents.data() + bytesWritten, contents.size() - bytesWritten);
if (written == -1)
{
perror("write");
break;
}
bytesWritten += written;
} while (bytesWritten < contents.size());
}
}
...
And that’s all there is to it. At this point the entire system has been described end-to-end: from the time the user adds a source file to the input folder to how they get a response back for their executed program. The next series of posts will cover how to refine a system a bit further from a deployment perspective; namely how to containerize the code using Docker and how to provide some resiliency using Kubernetes.